An up-to-date list is available on Google Scholar.
2024
-
×
![]()
Enhancing Parameter-Efficient Fine-Tuning of Vision Transformers through Frequency-Based Adaptation
Son Thai Ly, and Hien V Nguyen
arXiv preprint arXiv:2411.19297, 2024
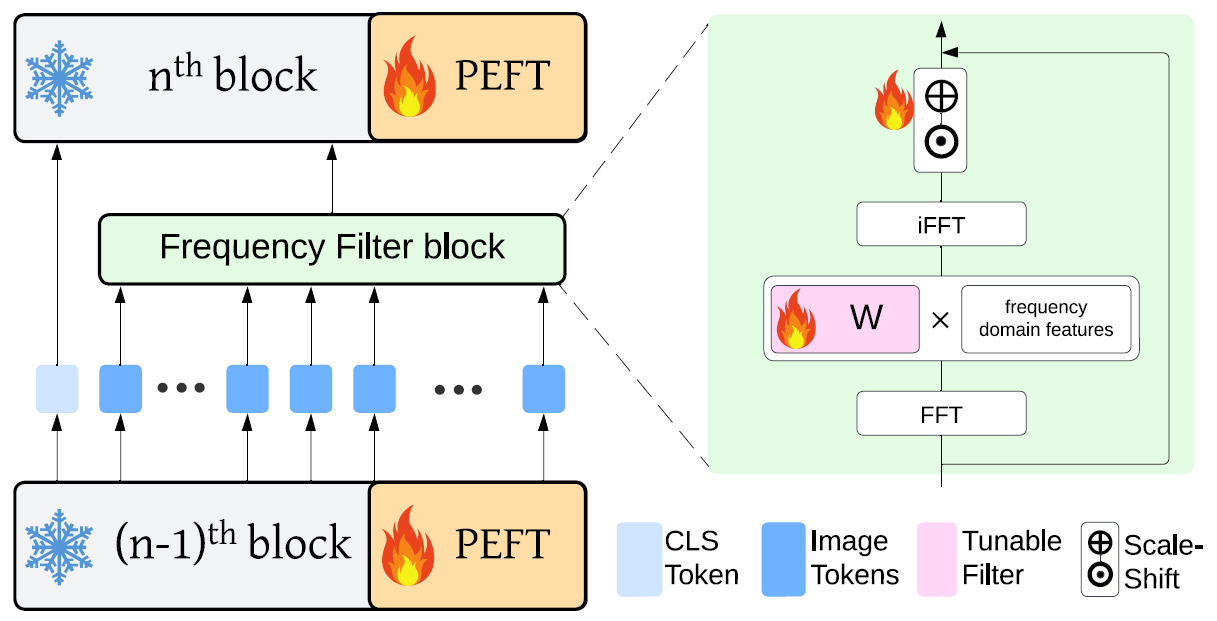
Adapting vision transformer foundation models through parameter-efficient fine-tuning (PEFT) methods has become increasingly popular. These methods optimize a limited subset of parameters, enabling efficient adaptation without the need to fine-tune the entire model while still achieving competitive performance. However, traditional PEFT methods may limit the model’s capacity to capture complex patterns, especially those associated with high-frequency spectra. This limitation becomes particularly problematic as existing research indicates that highfrequency features are crucial for distinguishing subtle image structures. To address this issue, we introduce FreqFit, a novel Frequency Fine-tuning module between ViT blocks to enhance model adaptability. FreqFit is simple yet surprisingly effective, and can be integrated with all existing PEFT methods to boost their performance. By manipulating features in the frequency domain, our approach allows models to capture subtle patterns more effectively. Extensive experiments on 24 datasets, using both supervised and self-supervised foundational models with various state-ofthe-art PEFT methods, reveal that FreqFit consistently improves performance over the original PEFT methods with performance gains ranging from 1% to 16%. For instance, FreqFit-LoRA surpasses the performances of state-of-theart baselines on CIFAR 100 by more than 10% even without applying regularization or strong augmentation.
-
×
![]()
Cellular data extraction from multiplexed brain imaging data using self-supervised Dual-loss Adaptive Masked Autoencoder
Son Thai Ly, Bai Lin, Hung Q Vo, Dragan Maric, and
2 more authors
Artificial Intelligence in Medicine, 2024
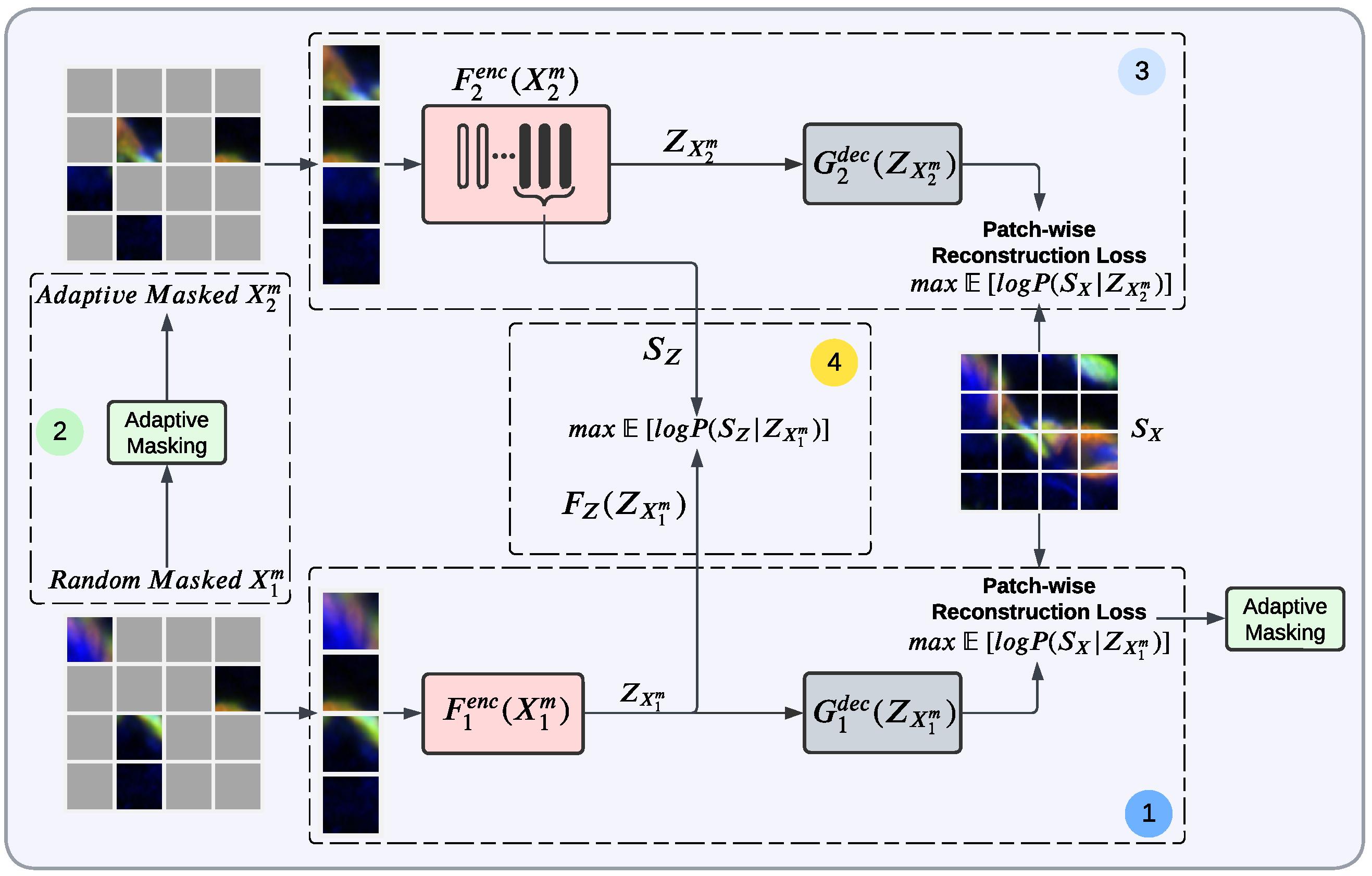
Reliable large-scale cell detection and segmentation is the fundamental first step to understanding biological processes in the brain. The ability to phenotype cells at scale can accelerate preclinical drug evaluation and system-level brain histology studies. The impressive advances in deep learning offer a practical solution to cell image detection and segmentation. Unfortunately, categorizing cells and delineating their boundaries for training deep networks is an expensive process that requires skilled biologists. This paper presents a novel self-supervised Dual-Loss Adaptive Masked Autoencoder (DAMA) for learning rich features from multiplexed immunofluorescence brain images. DAMA’s objective function minimizes the conditional entropy in pixel-level reconstruction and feature-level regression. Unlike existing self-supervised learning methods based on a random image masking strategy, DAMA employs a novel adaptive mask sampling strategy to maximize mutual information and effectively learn brain cell data. To the best of our knowledge, this is the first effort to develop a self-supervised learning method for multiplexed immunofluorescence brain images. Our extensive experiments demonstrate that DAMA features enable superior cell detection, segmentation, and classification performance without requiring many annotations. In addition, to examine the generalizability of DAMA, we also experimented on TissueNet, a multiplexed imaging dataset comprised of two-channel fluorescence images from six distinct tissue types, captured using six different imaging platforms
-
Anomaly detection in satellite videos using diffusion models
Akash Awasthi, Son Thai Ly, Jaer Nizam, Videet Mehta, and
4 more authors
In 2024 IEEE 26th International Workshop on Multimedia Signal Processing (MMSP)
Detecting anomalies in videos is a fundamental challenge in machine learning, particularly for applications like disaster management. Leveraging satellite data, with its high frequency and wide coverage, proves invaluable for promptly identifying extreme events such as wildfires, cyclones, or floods. Geostationary satellites, providing data streams at frequent intervals, effectively create a continuous video feed of Earth from space. This study focuses on detecting anomalies, specifically wildfires and smoke, in these high-frequency satellite videos. In contrast to prior endeavors in anomaly detection within surveillance videos, this study introduces a system tailored for high-frequency satellite videos, placing particular emphasis on two anomalies. Unlike the majority of existing Convolution Neural Network-based methods for wildfire detection that rely on labeled images or videos, our unsupervised approach addresses the challenges posed by high-frequency satellite videos with a high intensity of clouds. These Convolution Neural Network-based methods can only identify fires once they have reached a certain size and are susceptible to false positives. We frame the challenge of wildfire detection as a general anomaly detection problem. Introducing an innovative unsupervised approach involving diffusion models, which are state-of-the-art generative models for anomaly detection in satellite videos, we adopt a “generating-to-detecting” strategy. Performance evaluation, measured through AUC-ROC, underscores the superior efficacy of the diffusion model over CNN and Generative Adversarial Networks-based methods in detecting anomalies in these high-frequency satellite videos characterized by a high intensity of clouds. The dataset utilized can be accessed at this location.
2023